

This is the second post in our series covering ingesting logs into Q:CYBER and writing detections using our streaming rule engine.
In the first part, Q:CYBER Ingesting Windows Event Logs, we covered how to setup a new log source in the platform, configure NXLog to forward Windows Event Logs (WEL) through our QOMLINK Virtual Appliance (QLA), and how to setup a parser; all in a matter of a few minutes.
Now that logs are streaming into Q:CYBER we can begin to write detections using the rules builder workflow. But before we do it’s important to understand how rules are evaluated against logs in Q:CYBER and how it’s different from a number of other products on the market.
Scheduled Query Approach
It is common in SIEM products to see rule-based detections written as scheduled search queries that are executed against logs already stored in the database. Most of the new cloud-native SIEMS take this approach. The way you typically see this implemented is to enter a query and then select run periodically - say: once per day, hour, even every minute in some cases. One of the potential problems with scheduled queries is that, depending on the periodicity, you may not be getting alerted to issues as quickly as possible. This is not a true event-oriented processing architecture. If a detection against Pass-the-Hash or Kerberoasting attacks for example are only running, say every 20 mins, then there’s a possibility that an attacker can go unnoticed while you are waiting for the next scheduled run. Of course a way around that is to just schedule every query to run every minute or even every second if the product supports it, and suffer the additional compute load and cost burden. This is just one of the problems we considered when designing a true streaming rules engine as one of the detection options in Q:Cyber.
After a lot of review and planning, we ultimately decided on the following simplified system requirements:
- Must allow the user to define custom rules against a variety of data sources
- Must evaluate every rule as soon as a log record enters the platform to achieve the fastest possible detection time
- Must have the capability to evaluate against windows of time to enable behavioral based detections
Enter Streaming Rule Evaluations
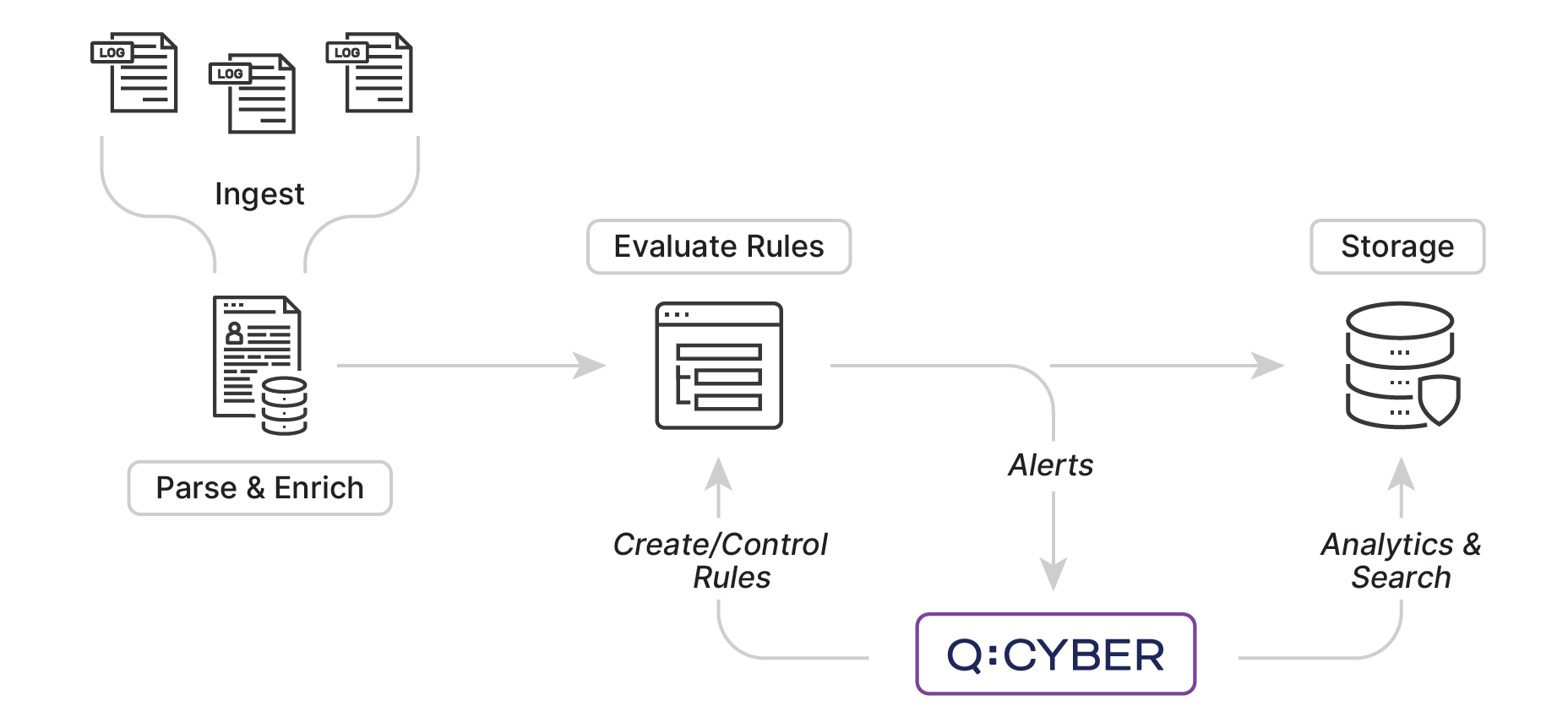
It turns out that we already had the foundation needed in Q:OS to build a detection engine that met our requirements above. Building on existing streaming analytic capabilities, our rules engine was designed as a multi-stage pipeline consisting of ingest, parse, evaluate, and store stages.
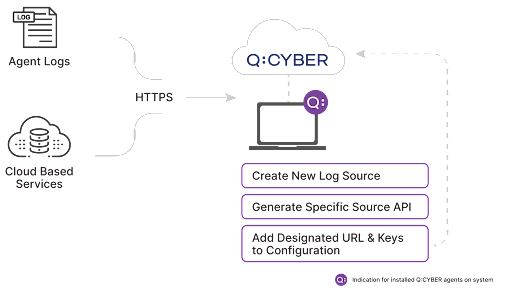
As detailed in the first post in this series, when you create a new Data Source in Q:CYBER, the platform first orchestrates the necessary services and creates the ingest stage of the pipeline which allows you to start sending data to the platform.
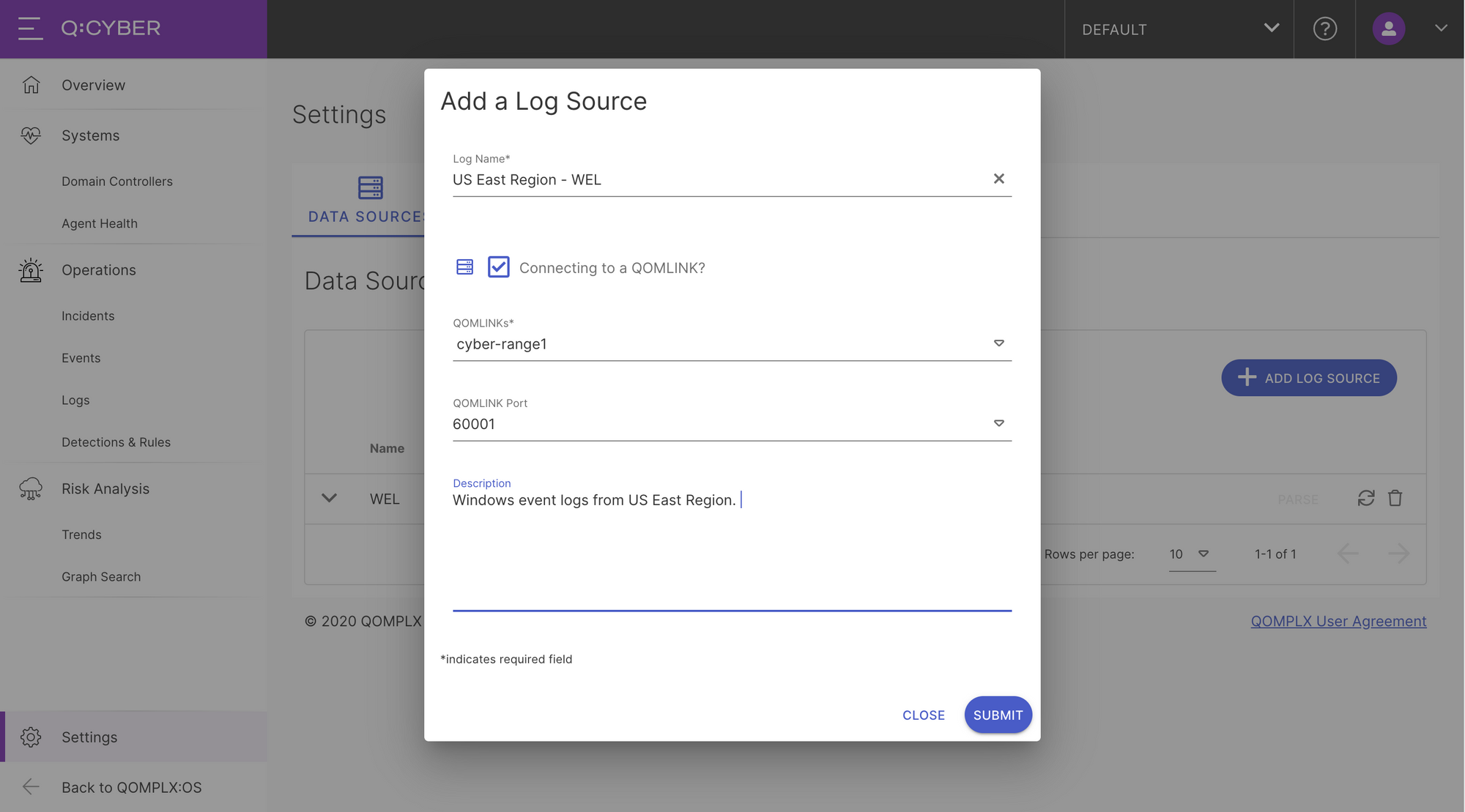
Once logs are successfully streaming into the ingest stage you create the parse stage by going through the parser workflow which includes selecting a parser type, testing it against the streaming logs, and mapping the necessary fields such as event time.
With the ingest and parsing stages in-place the pipeline is fully operational and any log received will be ingested, parsed, and ultimately stored in our various data stores. The next stage in the pipeline consists of evaluating any rules that you enabled in Q:CYBER. Rules consist of conditional statements that evaluate against key-value mappings in the logs and every rule is evaluated against every log record as it enters the pipeline. This effectively gives you a detection time limited only by the travel time of your logs.
Q:CYBER includes over 40 rule templates designed to detect a variety of common attacks against identity infrastructure with more added all the time. Additionally, users can easily modify existing templates to create whole new detections from scratch using the Q:CYBER Rule Builder. In the next post in the series we’ll walk through how to use the rules builder to build basic detections.




Interested in learning more?
Subscribe today to stay informed and get regular updates from QOMPLX.